Remote-Access CRDT-Wrapped Multi-Writer-Enabled Immutable File Format
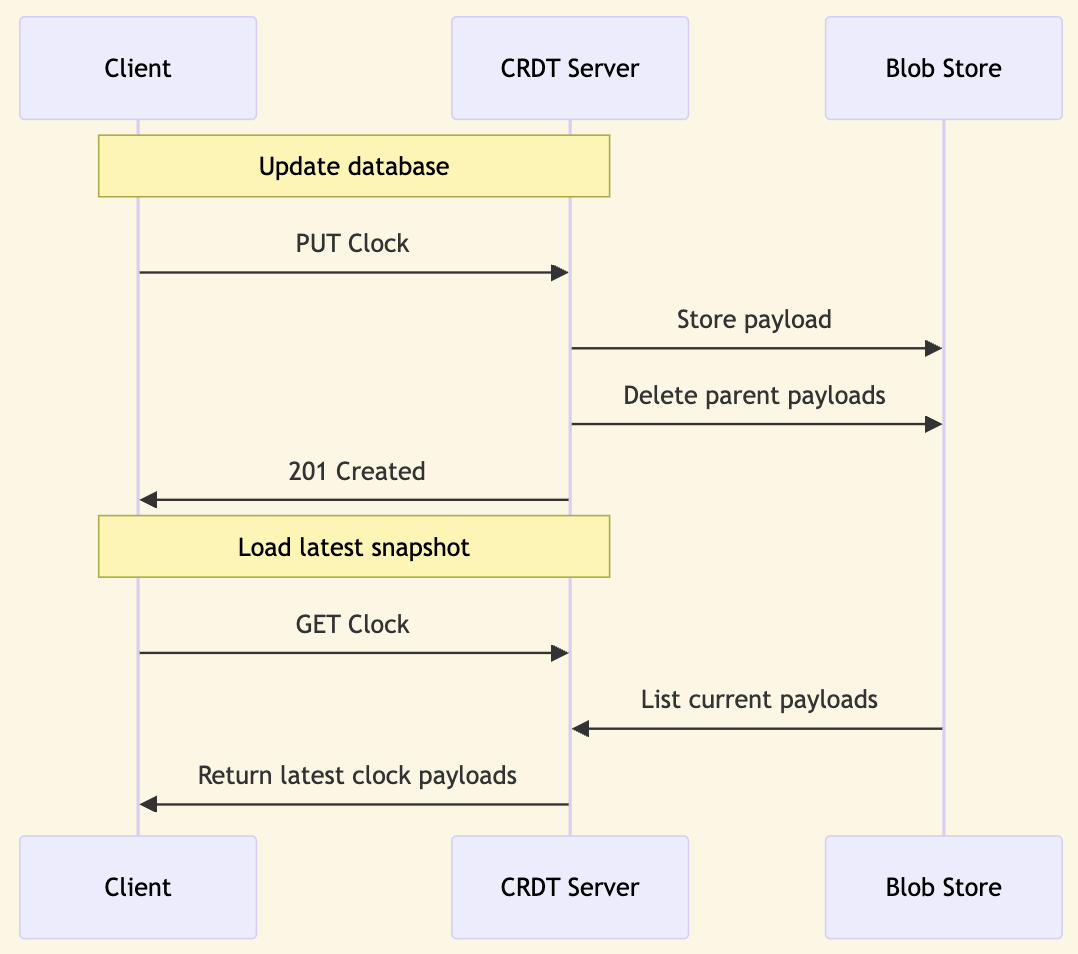
Fireproof records each transaction as an immutable, encrypted file in local storage. These files are then replicated to the cloud. A clock server is maintained in the cloud to allow clients to load the most recent version of the database. This clock contains one or more pointers to database snapshots. To load the latest database state, the client retrieves all current snapshots from the clock and merges them with any local updates into a new snapshot of the local database.
Once the snapshot files are uploaded to the cloud, the clock is updated to include the new snapshot and remove references to any snapshots that were merged into the local database. This process ensures that the number of snapshots a new client needs to load is minimized, while also ensuring that snapshots remain accessible until they are merged.
This system is implemented as a two-layer CRDT. The inner CRDT, stored within the encrypted local files, consists of the database data represented as a deterministically mergeable event log. The outer CRDT, the focus of this article, is the clock as described above. This outer CRDT can be utilized by other databases, CRDTs, and immutable storage engines to provide a multi-writer-enabled, remote-access, immutable, encrypted CRDT file format. This outer CRDT can be used to provide replication and encryption for any data structure that can be merged deterministically. We hope to see many projects using it, and we are happy to help with integration.
It's worth noting that this client/server model is optional, and Fireproof instances can also sync directly with each other. This article focuses on the mechanics of a cloud relay, but understanding how the wrapped CRDT works will also help if you are building a peer-to-peer sync solution.
This article will first explain the concept of a two-layer CRDT and its implementation in Fireproof, then delve into the specifics of the outer CRDT and its role in the system. We'll explore how the outer CRDT can be used by other projects to add encryption and replication to their data structures.
The Outer CRDT
In the Fireproof client/server CRDT system, every outer CRDT update operation comprises a unique identifier, a list of parent identifiers, and a payload. The parent identifiers represent previous payloads that have been merged into the new payload. The payload, while encrypted and opaque to the outer CRDT, serves as a database snapshot pointer in Fireproof.
A unique identifier is assigned to each payload. The parent list contains identifiers corresponding to the payloads that have been merged into the new payload data. While this payload data is opaque to the outer CRDT, it is used as a database snapshot pointer by Fireproof. It's worth noting that other CRDTs may utilize different types of payloads within this wrapper system. Additional use cases for the storage system are discussed later in the article.
Updating the CRDT
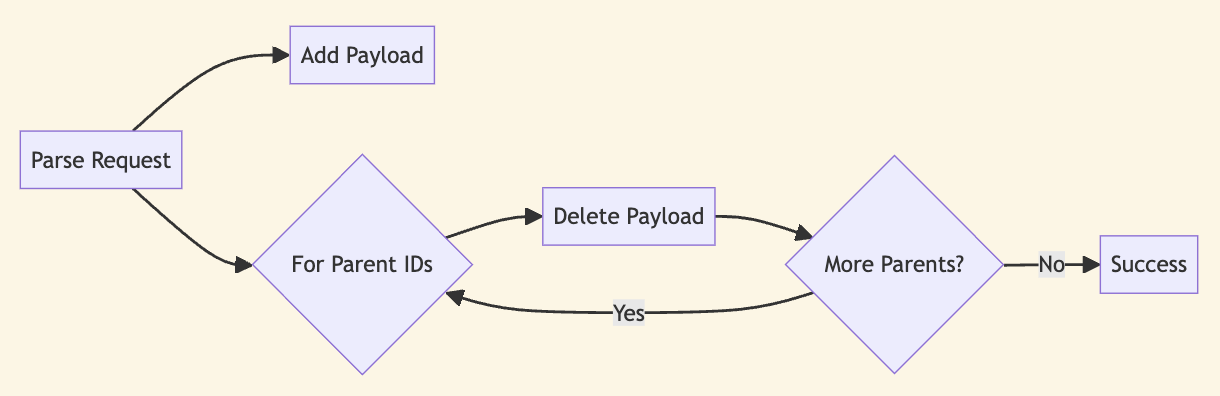
The CRDT server saves the payload in the blob store, using the unique identifier as the key. It then removes all payloads linked to the parent identifiers.
This process limits the number of payloads, ensuring that clients only replicate the latest version of the database. Additionally, the server refrains from advertising any payloads that have been merged into newer ones.
Implementation Focus, Netlify Edge Functions
Here are excerpts from the server-side implementation of the CRDT system. This code handles writes. Here we are using Netlify Blobs to store our metadata objects and data files. On read, we take advantage of the list feature to simplify our implementation. Fireproof is easy to integrate with almost any backend.
First, we import Netlify Blobs and get the 'meta' store.
import { getStore } from '@netlify/blobs'
// ...
const meta = getStore('meta')
Then, the server destructures the request body into 'data', 'cid', and 'parents'. These correspond to the payload data, unique identifier, and parent identifiers respectively. Check out the original code here.
if (req.method === 'PUT') {
const { data, cid, parents } = (await req.json())
The data is set in the 'meta' store with the key being a combination of 'dbName' and 'cid'. The dbName prefix is used in the GET API for listing active payloads.
await meta.set(`${dbName}/${cid}`, data)
After the data is saved, for each parent in the 'parents' array, the corresponding entry is deleted from the 'meta' store.
for (const p of parents) {
void meta.delete(`${dbName}/${p}`)
}
A response is returned with a status of 201 and a body containing a JSON stringified object with 'ok' set to true.
return new Response(JSON.stringify({ ok: true }), { status: 201 })
}
In summary, the server-side implementation of a CRDT write works as follows:
- The server destructures the request body into 'data', 'cid', and 'parents', representing the payload data, unique identifier, and parent identifiers respectively.
- The data is then set in the 'meta' store with the key being a combination of 'dbName' and 'cid'.
- Each parent in the 'parents' array has its corresponding entry deleted from the 'meta' store.
Reading the CRDT
When the client requests the current version of the CRDT, the server responds by listing all the currently active payloads for the current database. These payloads can be managed using any data structure, depending on the host environment. For instance, in Netlify, the list capability of Netlify Blobs is used to track the payloads.
Implementation Focus, Netlify Blobs
In the case of a GET request, the server lists all the currently active payloads for the current database. This is achieved by listing all blobs in the 'meta' store that have a prefix of 'dbName'.
const meta = getStore('meta')
const { blobs } = await meta.list({ prefix: `${dbName}/` })
Each blob is then retrieved from the 'meta' store by its key (in Fireproof, the content-identifier, but this can be any unique key). The server returns an object for each blob, containing its 'cid' and 'data'.
const entries = await Promise.all(
blobs.map(async blob => {
const data = await meta.get(blob.key)
return { cid: blob.key.split('/')[1], data }
})
)
Finally, a JSON response is returned, which contains a JSON stringified array of 'entries'.
return new Response(JSON.stringify(entries), { status: 200 })
}
The client can use the data returned by the server to load the complete snapshot for each payload. The client can then merge the payloads into a new snapshot of the local database, and save it back with a new clock payload.
In summary, the server-side implementation of a CRDT read works as follows:
- Retrieve all records in the metadata store that match the database name
- For each record, fetch its data from the metadata store, and create an object containing its unique identifier and data
- Send a response with a status of 200 and a body containing a JSON stringified array of these objects
This simple mechanism allows the CRDT server to work with all sorts of clients, including the Fireproof database.
Client Operations
Clients maintain an internal list of parent identifiers. They add to this list when they merge a new remote payload. Alternatively, they replace it with a single payload when it is committed to the remote clock. So the client always has a list of parents corresponding to payloads they have just written, or to payloads they have just merged locally.
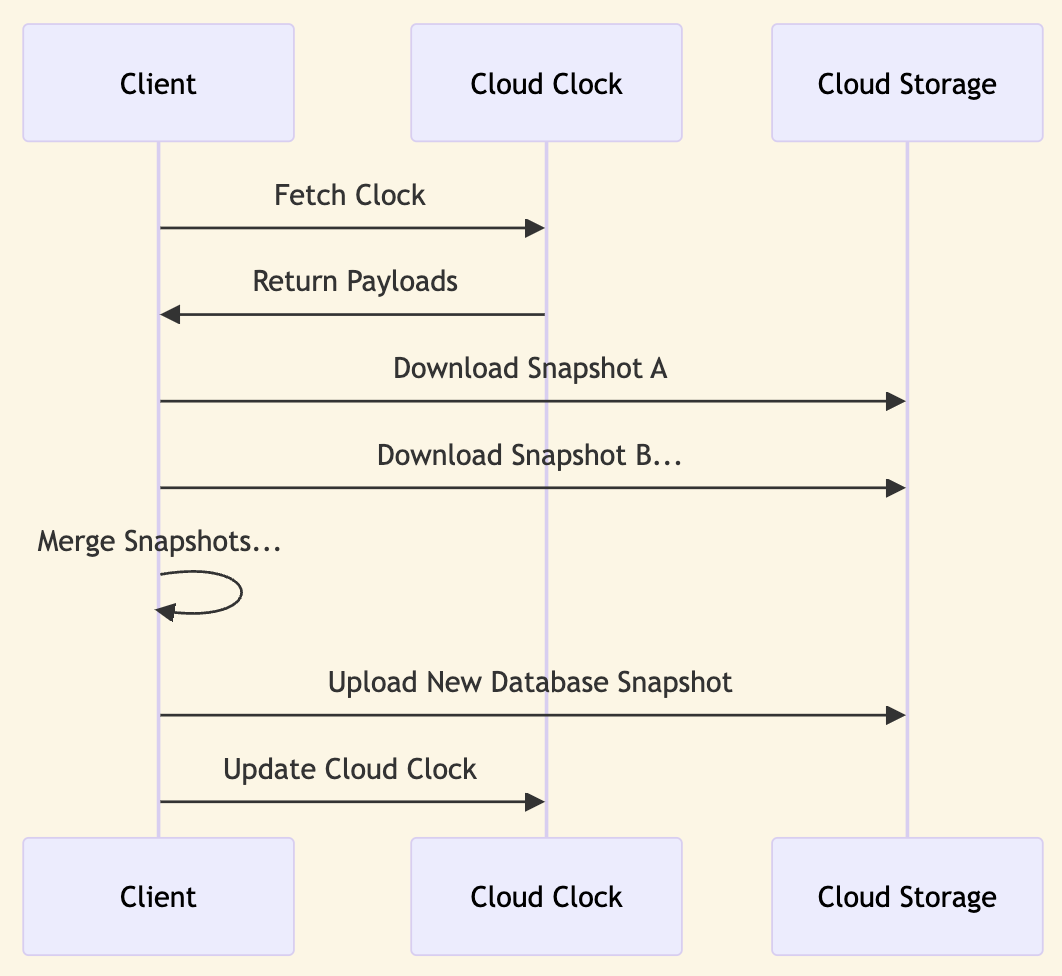
By following this mechanism, clients clean up after themselves as they go. Each write also removes payloads for older versions of the database that the client previously wrote. This prevents the accumulation of payloads over time, which could result in redundant merge operations by clients. For instance, if a client reads multiple payloads and merges them, on its next write it will replace all of them with the new payload as the parent. This way normal client operation prunes the list of payloads by merging them and writing back. Concurrent updates will be applied as new payloads in parallel, and future client reads will merge them and write back a new payload.
This ensures the set of payloads is kept pruned to the minimum number of payloads, without the chance of losing any data. It converges, so each client sees a dataset that is the result of merging every payload that has run through the clock. This is the eventual consistency property of the system.
Implementation Focus, Fireproof Netlify Connector
When the client retrieves the current version of the CRDT, it decodes and applies a list of payloads. The Netlify Connector's role here is to decode and return these payloads, not to apply them.
First, we fetch the CRDT entries from the Netlify edge function. It will use the list operation detailed above to give us the current set of CRDT payloads.
const fetchDownloadUrl = new URL(`/fireproof?meta=${params.name}`, document.location.origin)
const response = await fetch(fetchDownloadUrl)
if (!response.ok) throw new Error('Failed to download meta: ' + response.statusText)
const crdtEntries = await response.json()
Next, we decode the base64 encoded payload data for each entry.
const events = await Promise.all(
crdtEntries.map(async (entry: any) => {
const base64String = entry.data
const bytes = Base64.toUint8Array(base64String)
const event = this.decodeEventBlock(bytes)
return event
})
)
We then update the list of parents based on the payload IDs.
const cids = events.map(e => e.cid)
this.parents = [...new Set([...this.parents, ...cids])]
Finally, we return the bytes for each event, to be utilized by the inner CRDT's merge process.
return events.map((e) => e.bytes)
}
The array of returned bytes, each of which in Fireproof consists of the database encryption key and the most recent snapshot id, are used to load snapshot files from remote storage. These snapshots are then merged into a new local snapshot, which is subsequently committed back to the remote clock using a new payload, thereby completing the client-side implementation of a CRDT read and merge operation.
The difficult part
If a client incorrectly represents a payload as containing merge information from a parent that it does not reflect, the server will delete that parent payload. This could potentially lead to data loss if other clients have not yet fetched the unmerged payload. Therefore, the accuracy of the system depends on the client only listing parents that it has successfully merged. This is a critical area where correctness tests and fuzzers should focus when validating Fireproof.
Where this can get tricky, is if there is a payload that can't be merged due to data availability or corruption. In this case, no clients will merge it, and it will remain in the system indefinitely, potentially compromising client performance as they try to reconcile the unmergeable payload with each update. In production, the administrator can manually remove the unmergeable payload, and clients will continue to function normally. In the future, we may add a mechanism to automatically log and remove unmergeable payloads.
The Inner CRDT
We have only discussed the outer, server-managed CRDT. The inner CRDT is encrypted and opaque to the outer CRDT, and it is the portion that implements eg, the database API. Other users of this system may use other types of inner CRDTs. What they have in common is that the inner CRDT is merged and managed by the client, with pointers recorded in the outer CRDT. This allows the client to save inner CRDT payloads as files, and use the outer CRDT to ensure clients receive the correct payloads.
You can think of the system as described so far as a multi-writer-enabled remote-access immutable append-only CRDT file format. Any program that follows the rules about merging payloads can use this system to manage its data. So that means any CRDT with a deterministic serialization can potentially plug into Fireproof's storage layer to provide replication and encryption. What kinds of data structures are used to merge and access data are up to the inner CRDT.
There is currently an effort underway to extract this interface as an independent module. This will allow other CRDTs (or anyone looking for an encrypted alternative for IPFS replication) to use the library, giving them access to the full suite of Fireproof sync, storage, and sharing adapters.
Fireproof's Inner CRDT
In Fireproof the inner CRDT uses Alan Shaw's immutable Pail data structure. This implements the deterministic merge algorithm for the database event log. Basically, it's the data structure that supports get and put by document ID, as well as allowing safe merges of databases across multiple devices.
In the outer CRDT, each payload is a database snapshot pointer, linking to the encrypted CRDT. The encrypted CRDT is a complete snapshot of the database state and can be queried, updated, and merged by the client. Each update creates a new encrypted storage file and a new metadata payload in the outer CRDT.
The outer CRDT doesn't care if the inner data structure is Pail or any other content-addressed data structure. The only thing that matters about that structure as far as the wrapping CRDT is concerned, is that its operations are commutative, associative, and idempotent. This means that as long as the encrypted CRDT knows how to merge its operations in any order, the wrapping CRDT can safely manage the payloads.
Eventual Consistency of the System
This system possesses a unique property. Payloads are not removed from the CRDT until they are merged and a new payload cites them as a parent. Consequently, the system can only accumulate new changes, and existing changes will not be discarded until they are merged. This means that the system is eventually consistent, converging on the same state for all clients.
The system's most significant potential fault could arise if the client fails to merge all payloads but nevertheless lists them as parents to a new payload. This action would prompt the server to discard those payloads, potentially leading to data loss. Therefore, the system depends on the client maintaining an accurate list of parent payloads. This area is a prime target for correctness tests and fuzzers during the validation of Fireproof.
Use Cases for the Storage System
Numerous CRDTs can be mapped to mergeable payload pointers as described above. For those seeking encrypted storage for systems like Y.js or Automerge, this module can provide a secure, multi-writer-enabled, remote-access immutable append-only CRDT file format, encapsulating the inner CRDT of their choice.
Furthermore, developers who have built applications that rely on globally available clear text IPFS blocks can easily target this blockstore, gaining encryption and replication "for free". This includes access to all of the Fireproof connectors and storage options, enabling applications that might have previously required a complex network to operate local-first in the browser or edge function.
If you want to contribute to this effort, please join the discussion on GitHub or Discord.